Abstract Both PHP and JavaScript are frequently being targeted for exploiting web applications. This article elaborates on the idea of building a set of virtual machines on top of each programming language. As a result a single type of bytecode can be executed by both VMs. Particular emphasis is put on designing virtual machines to be most suitable for code obfuscation in a post exploitation scenario.
Tuesday, June 1. 2010
Virtual Meta-Scripting Bytecode for PHP and JavaScript
Tuesday, March 23. 2010
Asterisk and the Blink
![]() It's just one of those spring days where your may wonder how to control your friendly BlinkenLights neighbourhood building with Asterisk. Ordinarily the installation comes with a control program called BlinkenLights Chaos Control Center (BLCCC) which can be seen as a jukebox controller handling movies and games. The BLCCC expects incoming ISDN phone calls to be relayed by a UDP based protocol. A suitable Asterisk AGI application can now take over the role of a mediator between ISDN and BLCCC, thus transparently substitute a real ISDN line.
It's just one of those spring days where your may wonder how to control your friendly BlinkenLights neighbourhood building with Asterisk. Ordinarily the installation comes with a control program called BlinkenLights Chaos Control Center (BLCCC) which can be seen as a jukebox controller handling movies and games. The BLCCC expects incoming ISDN phone calls to be relayed by a UDP based protocol. A suitable Asterisk AGI application can now take over the role of a mediator between ISDN and BLCCC, thus transparently substitute a real ISDN line.
The PoC version of this mediator program is the newest extension to the PoC Telephony Application Suite.
Sunday, October 11. 2009
AVR SPI und USBasp
 Wir sehen ein
Wir sehen ein Wednesday, June 10. 2009
Das Eingabefeld
![]() Eine spontane Frage: Du siehst ein Eingabefeld. Was tippst du ein?
Eine spontane Frage: Du siehst ein Eingabefeld. Was tippst du ein?
Ich habe diese Frage gestellt und mehrere Antworten erhalten:
Hallo Du bist doof. 1 Who am I? srcjbhenoth (random)
foo bar bla boo test fnord 42 Mr. Foo Bar
"><script> ';drop database;-- 0000 admin abc aaa %00 ../.. `ls` 12345 테스트
Saturday, May 9. 2009
VirtualDocumentRoot and ImaginaryProtection
Wednesday, May 6. 2009
SSL und andere Geschichten
Monday, November 24. 2008
Playing hide and seek in a flash
Imagine a warm and bright Saturday afternoon the summer you were just eight years old. Can you remember playing hide and seek with other children from the neighbourhood or from school? Everybody likes to be the one hiding somewhere. You choose a seemingly hidden spot and wait. After a while it would become boring, if the spot is just too well concealed, so you declare a time-out and win the round. However once a hideout is known to any of the seekers, you will be found eventually. From the seeker's perspective, most likely hiding spots are being searched first, depending on where the seeker would hide if he were on the opposing team. Most likely, some even obvious spots will be missed during the first round, like right on top of you inside the trees. Seekers learn and will check there first in the next round. However the hiding party is learning as well, always coming up with tons of new hideouts and ideas to conceal themselves even better. But they will all be found eventually. It is not surprising that discovering at least one person is rather easy if most of the group are hiding and few are seeking, so we'll assume the opposite: Many are searching, few are hiding.
The same game may be applied to Flash/SWF. An attacker wants to execute fraudulent code on a victim's machine. In this case, it should be sufficient to execute arbitrary code inside someone's flash player. The "seeker's" objective is (1) to recognise an attack, preferably before execution, and (2) to know the threat in detail. Obviously, the attacker's role in this game consists of suitable counterparts: (1) Hide the existence of an attack, at least until the code is being executed without being found before and (2) obfuscate the code to discourage easy analysis.
You may see certain similarities to the game, virus writers and the antivirus industry have been playing for some time now. The word 'virus' in this context may stand for trojan horses, spyware, malware or any kind of unwanted software. The dominating virus detection technique - at least referring to static analysis - is a signature match against a dictionary of known viruses (see antivirus software). Once a virus has been identified, a fingerprint of its program code or parts of the code results in a new signature for the dictionary. Round one for the hide and seek goes to the seekers. The natural response to avoid signature detection is a self-modifying code, otherwise known as polymorphic or metamorphic code (see computer virus).
Once again, applied to Flash, a signature approach seems appropriate. Flash code can not (easily) alter and strore itself. Even though Flash files are usually not stored locally for constant analysis by virus checkers, the static nature can be observed in the wild. But there is no reason, why a server should not be able to recreate a different version of the same SWF for each request, which is somewhat like an outsourced metamorphism. So, attackers score round two.
For the analysis of non-static code with static function range, heuristic approaches come to mind. [ Georgia Frantzeskou, Efstathios Stamatatos, and Stefanos Gritzalis - Suppοrting the Cybercrime Investigation Process: Effective Discrimination of Source Code Authors Based on Byte-Level Information - 2007] suggested a statistical classification method based on n-grams (see Ngram). The front row application for n-grams is language detection of written text. The occurrence of every N successive characters (including whitespace) of a text is counted and then compared relatively to a reference count of known language.
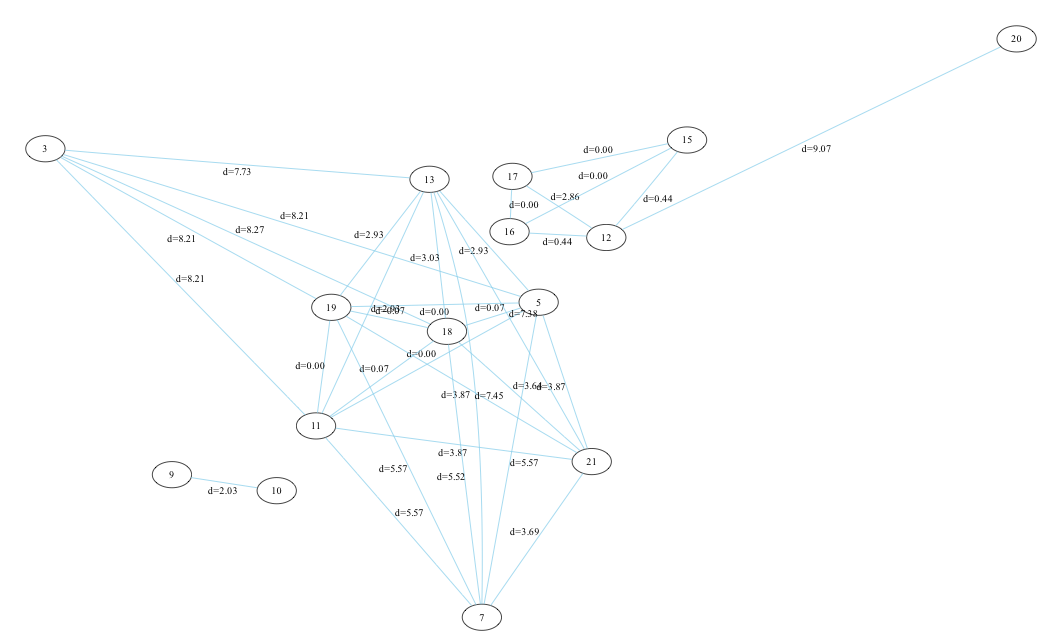
statistical classification - n-gram over bytecode ops
This classification method can be applied to Flash as well. Instead of N characters of a text, we'll take a sequence of N ABC OP-codes (aka. AVM2 bytecode). The figure shows a graph representation of several arbitrarily chosen SWF9/10 files and their distance based upon the n-gram analysis. (n=3, hidden edges by distance threshold).
Three clusters become apparent: {9,10}, {17,16,12,15,20} and {3,13,19,11,18,5,21,7}. Clustering is an expression of similarity between the SWF's bytecode. N-gram profiles contain characteristics of the compiler or IDE, std. libraries and the code's author(s), each with different intensity. I'd say, that's another point for the seekers.
Now, in order to defy heuristics, two ways pop into consciousness. Either imitate another profile's appearance by adding NOPs and dead code, or hide the bytecode entirely. While imitation techniques can be matched up by even more advanced filtering and statistical methods, we are going to explore more hiding and obfuscation on the byte level. The AVM2 incorporates a byte loader, which can be used to load and evaluate ABC bytecode during runtime. Consider that we can hide our code anywhere inside the SWF or load seemingly unsuspicious data from external sources - e.g. a picture, sound file, timing data or even data encoded as fake dead code. The data would then be transformed back to our original payload and handed over to the byte loader. Of course, our transformation algorithm and the byte loader itself must undergo a procedure, too, in order to look as harmless as possible. Fortunately there are numerous everyday tasks to be solved by data conversion and loading algorithms, so that our few lines of code can be fingerprinted heuristically without arising any suspicion.
With alchemy Adobe hands out a toolkit for fast ByteArray manipulation free of charge, which happens to coincide with bytecode obfuscation/deobfuscation as described. Hence Adobe scores yet another point for the attackers - yay.
All these elaborations are by no means only of theoretical nature. erlswf has been specifically designed to match the needs of SWF bytecode analysis up to this point in this train of thoughts.
A few concluding remarks: The game of hide and seek goes on forever. If anyone wondered what our current state of the game was, my personal guess would put it somewhere near the end of round one. That means, there is more to look forward to and much more to come.
Thursday, September 11. 2008
Die Tüten-Tüte
Thursday, September 4. 2008
django & CouchDB - a match made outside of heaven
First of all, if you don't already know django and CouchDB, take a look at their websites. You might ask "Why? Why this combination?". Both django as an application framework and CouchDB as a database engine are state of the art technologies. So, why not? While searching the net, numerous forums and websites propagate their user's silent wish to incorporate a CouchDB backend into django: 1 2 3
Let's take a closer look. django's backend engines are all SQL based and suitable for relational data organisation - oracle, mysql, postgres, sqlite. That means tables can be created according to a data description and have relationships, e.g. a group contains many users and a user can be in many groups; both users and groups have predefined attributes such as a name. CouchDB on the other hand is document based and schemafree. Each document can be structured differently. You just throw whichever data you have serialised as JSON object into the database. That's it. A document could be an address or details of a book in your personal library or any other data representable as JSON. As a bonus, each document may have any number of file attachments.
Now, in order to use django and CouchDB hand in hand there are two major strategies, both with it's catches:
One. Develop a proper and seamlessly integrating django model backend using CouchDB. Since most database queries in django use either django's query class django.db.models.sql.query.Query or plain SQL, a new django model must either be able to parse SQL or implement all functions of this query class. (You could also re-implement each save() function of all uses of a django model for starters, but that would be the opposite of an abstracted model component.)
Two. Completely ignore the existence of a model abstraction and implement data storage directly into django views -- who needs MVC anyway. PHP versions 1-3 have taught us to implement everything inside a single view anyway  A nice example can be found here.
While you may already have thoughts about how easy it is to implement a SQL parser, map a relational model upon a document based model and stick it all together into a django model backend (which - by the way - is quite possible), I found that django rather emphasises the "rapid" in rapid development. So, we'll linger with option number two for the moment. Let's see, what we can use of the django world now:
- urlpatterns
- templates
- views
- the file upload handler
- sessions (with SESSION_ENGINE = 'django.contrib.sessions.backends.cache')
- caching (CACHE_BACKEND = 'locmem://')
- the authentication backend (hm?)
A nice example can be found here.
While you may already have thoughts about how easy it is to implement a SQL parser, map a relational model upon a document based model and stick it all together into a django model backend (which - by the way - is quite possible), I found that django rather emphasises the "rapid" in rapid development. So, we'll linger with option number two for the moment. Let's see, what we can use of the django world now:
- urlpatterns
- templates
- views
- the file upload handler
- sessions (with SESSION_ENGINE = 'django.contrib.sessions.backends.cache')
- caching (CACHE_BACKEND = 'locmem://')
- the authentication backend (hm?)
In order to use the authentication backend without a django model backend, sessions and caching must already be configured as above, django.contrib.sites must be disabled, and a custom auth backend must be implemented as documented. Then, it is advisable to prevent anyone from calling save() or get_and_delete_messages() on a User object:
