Imagine a warm and bright Saturday afternoon the summer you were just eight years old. Can you remember playing hide and seek with other children from the neighbourhood or from school? Everybody likes to be the one hiding somewhere. You choose a seemingly hidden spot and wait. After a while it would become boring, if the spot is just too well concealed, so you declare a time-out and win the round. However once a hideout is known to any of the seekers, you will be found eventually. From the seeker's perspective, most likely hiding spots are being searched first, depending on where the seeker would hide if he were on the opposing team. Most likely, some even obvious spots will be missed during the first round, like right on top of you inside the trees. Seekers learn and will check there first in the next round. However the hiding party is learning as well, always coming up with tons of new hideouts and ideas to conceal themselves even better. But they will all be found eventually. It is not surprising that discovering at least one person is rather easy if most of the group are hiding and few are seeking, so we'll assume the opposite: Many are searching, few are hiding.
The same game may be applied to Flash/SWF. An attacker wants to execute fraudulent code on a victim's machine. In this case, it should be sufficient to execute arbitrary code inside someone's flash player. The "seeker's" objective is (1) to recognise an attack, preferably before execution, and (2) to know the threat in detail. Obviously, the attacker's role in this game consists of suitable counterparts: (1) Hide the existence of an attack, at least until the code is being executed without being found before and (2) obfuscate the code to discourage easy analysis.
You may see certain similarities to the game, virus writers and the antivirus industry have been playing for some time now. The word 'virus' in this context may stand for trojan horses, spyware, malware or any kind of unwanted software. The dominating virus detection technique - at least referring to static analysis - is a signature match against a dictionary of known viruses (see antivirus software). Once a virus has been identified, a fingerprint of its program code or parts of the code results in a new signature for the dictionary. Round one for the hide and seek goes to the seekers. The natural response to avoid signature detection is a self-modifying code, otherwise known as polymorphic or metamorphic code (see computer virus).
Once again, applied to Flash, a signature approach seems appropriate. Flash code can not (easily) alter and strore itself. Even though Flash files are usually not stored locally for constant analysis by virus checkers, the static nature can be observed in the wild. But there is no reason, why a server should not be able to recreate a different version of the same SWF for each request, which is somewhat like an outsourced metamorphism. So, attackers score round two.
For the analysis of non-static code with static function range, heuristic approaches come to mind. [ Georgia Frantzeskou, Efstathios Stamatatos, and Stefanos Gritzalis - Suppοrting the Cybercrime Investigation Process: Effective Discrimination of Source Code Authors Based on Byte-Level Information - 2007] suggested a statistical classification method based on n-grams (see Ngram). The front row application for n-grams is language detection of written text. The occurrence of every N successive characters (including whitespace) of a text is counted and then compared relatively to a reference count of known language.
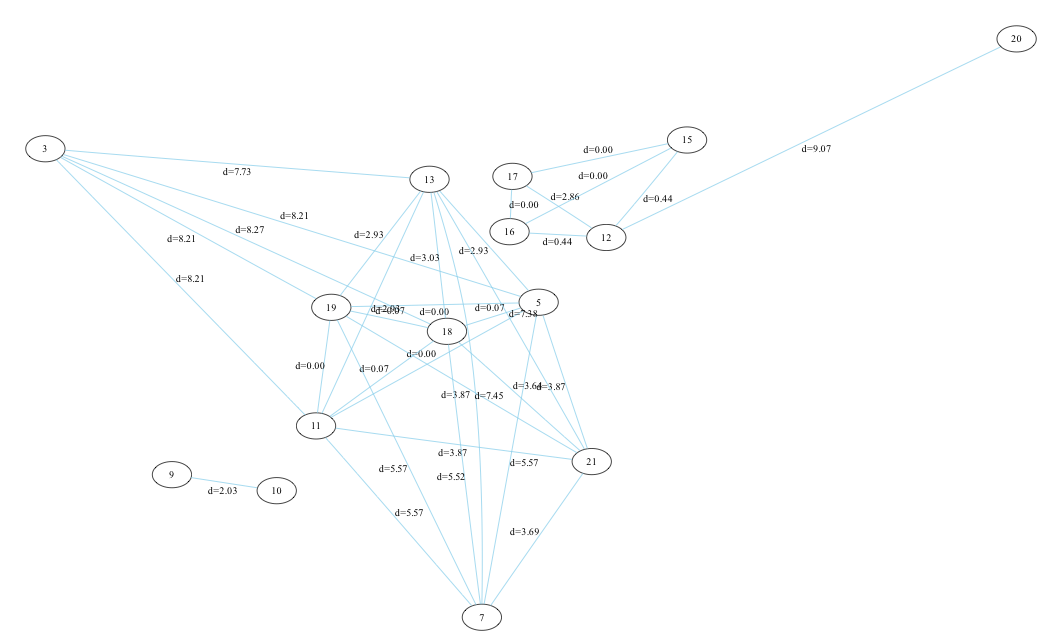
This classification method can be applied to Flash as well. Instead of N characters of a text, we'll take a sequence of N ABC OP-codes (aka. AVM2 bytecode). The figure shows a graph representation of several arbitrarily chosen SWF9/10 files and their distance based upon the n-gram analysis. (n=3, hidden edges by distance threshold).
Three clusters become apparent: {9,10}, {17,16,12,15,20} and {3,13,19,11,18,5,21,7}. Clustering is an expression of similarity between the SWF's bytecode. N-gram profiles contain characteristics of the compiler or IDE, std. libraries and the code's author(s), each with different intensity. I'd say, that's another point for the seekers.
Now, in order to defy heuristics, two ways pop into consciousness. Either imitate another profile's appearance by adding NOPs and dead code, or hide the bytecode entirely. While imitation techniques can be matched up by even more advanced filtering and statistical methods, we are going to explore more hiding and obfuscation on the byte level. The AVM2 incorporates a byte loader, which can be used to load and evaluate ABC bytecode during runtime. Consider that we can hide our code anywhere inside the SWF or load seemingly unsuspicious data from external sources - e.g. a picture, sound file, timing data or even data encoded as fake dead code. The data would then be transformed back to our original payload and handed over to the byte loader. Of course, our transformation algorithm and the byte loader itself must undergo a procedure, too, in order to look as harmless as possible. Fortunately there are numerous everyday tasks to be solved by data conversion and loading algorithms, so that our few lines of code can be fingerprinted heuristically without arising any suspicion.
With alchemy Adobe hands out a toolkit for fast ByteArray manipulation free of charge, which happens to coincide with bytecode obfuscation/deobfuscation as described. Hence Adobe scores yet another point for the attackers - yay.
All these elaborations are by no means only of theoretical nature. erlswf has been specifically designed to match the needs of SWF bytecode analysis up to this point in this train of thoughts.
A few concluding remarks: The game of hide and seek goes on forever. If anyone wondered what our current state of the game was, my personal guess would put it somewhere near the end of round one. That means, there is more to look forward to and much more to come.